
link to the github repo
What I’ll be talking about
In this blog post I will be talking about how I created a spam detector. This was my first machine learning project so I was very lost at first but as I learned more it was really cool learning how machine learning is used, ways in which people solve problems, and learning how I could solve my problem. I did not use any libraries but I know they exist and make things easier and I will be talking about in the blog post as well. One of the biggest essentials in machine learning is data. We need a lot of data to train o. I got the data from the UC Irvine Machine Learning Repository which you can also get as well. data
What the issue is
So the problem here is if we have incoming text or emails to a user how can we classify messages as spam or ham (not spam) so that we can prevent the user from getting a spam message therefore we have to create a spam detector using machine learning. First here are some things to know that I will be mentioning in this post.
Things to know
Supervised Machine Learning: So because we have the labels this is a machine learning project. This is something I had no idea about. There are other forms of machine learning such as unsupervised learning, semisupervised learning, and clustering.
Classification: In machine learning there are different types of tasks that can be done. Some of them are classification tasks such as KNN and naive bayes. Both these algorithms aim to classify something into a certain class. An example of this is this project. We are predicting whether a message is spam or ham so we are predicting the class of some data. Another big task in machine learning is predicting a numerical value. An example for this is linear regression,
Jupyter NoteBooks: Jupyter NoteBooks are a really cool tool that is commonly used in machine learning. They are great for visualazing data, etc.
What is ham?:
Ham is not spam. Here is an example from the data set of what spam is. Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's. And here is an example of what ham is. Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...
Splitting Data: In machine learning one of the most important things besides the data its self is splitting the data. Data is ussually split as 80% train data and 20% test data. Our train data is used to train our model and test our algorithms. The way in whic I split my data can be seen in my notebook but what I did was I used some code I got from a book to split the data whcih randomises the data then splits in. Because we would get new train and test data everytime I only ran it once and turn the data inso csv. Another thing that is important in splitting the data is that you have a even ammount of both types. Let’s say for example if for some reason once we split our data that our majority of data samples were only ham. Our model would not know what spam is therefore it would fail.
How dictionaries work: Dictionaries or hashmaps in programming is a data structure. It’s a way in which we can structure data by storing a key (some variable) and it’s value (some other variable). Let’s say for example
Attempt 1
My first algorithm was very simple. The idea was that my algorithm would take in a message which would then be made into a dictionary containing the words of the message as it’s keys. Once we had the dictionary we needed to store the spam and ham values of that word so we put a dictionary of values for the words set to 0. This would allow us to track the spam and ham values of each word and check if a message has a lot of spam words or not. For example if the word free appeared in the message it would have a larger spam value than a ham value so it would get marked as spam: 1 and ham: 0. Here is a sample run of what it would look like using the sentence hey are u free tonight.
Here is our dictionary with our words and keys.
words_dict = {
'hey': ['spam']: 0, ['ham'] : 0,
'are': ['spam']: 0, ['ham'] : 0,
'u': ['spam']: 0, ['ham'] : 0,
'free': ['spam']: 0, ['ham'] : 0,
'tonight': ['spam']: 0, ['ham'] : 0,
}
Since we now have our dictionary the next step is to look up our words in another dictionary that contains words and probabilities of them being spam or not already filled in. This will allow us to compare our message to see what our words probabilities of being spam or ham.
# Our dict
words_dict = {
'hey': ['spam']: 0, ['ham'] : 0,
'are': ['spam']: 0, ['ham'] : 0,
'u': ['spam']: 0, ['ham'] : 0,
'free': ['spam']: 0, ['ham'] : 0,
'tonight': ['spam']: 0, ['ham'] : 0,
}
# The dictionary we look up our words in
prefilled_dict = {
'hey': ['spam']: 10, ['ham']: 20,
'the': ['spam']: 7, ['ham'] : 10,
'u': ['spam']: 2, ['ham'] : 14,
'sky': ['spam']: 0, ['ham'] : 12,
'is': ['spam']: 6, ['ham'] : 10,
'blue': ['spam']: 0, ['ham'] : 15,
'free': ['spam']: 15, ['ham']: 4,
'cat': ['spam']: 0, ['ham']: 12,
'are': ['spam']: 14, ['ham']: 34,
'exclusive': ['spam']: 16, ['ham']: 3,
'tonight' : ['spam']: 9, ['ham']: 30,
}
Once we have compared our words our dictionary would have the values for each word and would look like this.
words_dict = {
'hey': ['spam']: 10, ['ham']: 20,
'are': ['spam']: 14, ['ham']: 34,
'u': ['spam']: 2, ['ham'] : 14,
'free': ['spam']: 25, ['ham']: 7,
'tonight' : ['spam']: 9, ['ham']: 30,
}
Now that we have the values for the words we can check which value is higher. In another function I passed in our dictionary where we would do this. The function would check if the spam value was higher than the ham value, if it was we would add 1 to the list and if not we add 0.So we have a list with ones and zeroes. If the list had more 1s than zeroes it was spam. Our current example of hey are u free tonight would look like this
words_nums = [0, 0, 0, 1, 0]
Because there are more zeeroes than there are ones this would be marked as spam. This algorithm did really bad on the training data. I don’t really remember the scores it got but I know it was really low that I didn’t bother using the test data. One of the main issues I had was not having words to compare it to which meant almost everything was set to ham. As I said earlier this algorithm looked at every word in the message and searched it up in a dictionary with prefilled words and values but that dictionary only had maybe 10 or so words already manually set by me. This wouldn’t have been such a bad idea if I had lots and lots of words but the issue with this is I would not know what to set their spam and ham values to. So with this came the idea for my next algorithm.
Attempt 2
After looking into possibilities of solving my issue with my first algorithm I had my new idea. The idea was that first we would set all the data (words) into dictionary form, where every word in the dataset would have its spam and ham value. This new algorithm would go through every message and clean the message (which I had not done previously) by removing punctuation and making every word lowercase. Doing this is good for many reasons one of them being. Once we have our clean message in a list form we can now input the words into the dictionary with their values (default to 1).
#####This function is for setting the words into the probability dictionary
def add_words_to_dict(sms_list:list):
"""
This function takes in a list as its argument and with
the items of those list we create a dictonary with the
words as keys. The value of the key are a dictionary
with 2 keys one of them being spam and the other ham.
The values to those are the words probability of it
being spam or ham
"""
for i in range(len(sms_list)):
# select current word
word = sms_list[i]
# if word is already there ignore it for now
if word in PROBS:
pass
elif word not in PROBS:
# if word is not in there set their ham and spam values to 1
PROBS[word] = {'spam' : int(1), 'ham' : int(1)}
The way in which I assigned the values to a word was by its label (this is supervised machine learning so we have the labels for each message). The algorithm had a function which would take its label as its argument and the message itself. Depending on the label it would add a point to its label value in the dictionary. If that is confusing here is the function.
##### This function is for assigning spam and ham values to words
def assign_vals_to_words(label:str, sms_list:list):
"""
This function takes in a string (label of sms) and the sms
as a list. Depending on the label we will add 1 to every
word on that list label value.
"""
spam = 'spam'
ham = 'ham'
if label == spam:
# for all spam sms in our train data sets
for i in range(len(sms_list)):
# select word
word = sms_list[i]
# add 1 to their spam values
PROBS[word][spam] += 1
elif label == ham:
# for all ham sms in our train data sets
for i in range(len(sms_list)):
# select word
word = sms_list[i]
# add 1 to their ham values
PROBS[word][ham] += 1
else:
pass
Once we ran that function our dictionay was filled with its values and looked like this. This is also only a sample because the actual dictioanry is much larger.
probabilities = {
'go': {'spam': 27, 'ham': 205}, 'until': {'spam': 6, 'ham': 20}, 'jurong': {'spam': 1, 'ham': 2}, 'point': {'spam': 1, 'ham': 12}, 'crazy': {'spam': 4, 'ham': 9}, 'available': {'spam': 4, 'ham': 14}, 'only': {'spam': 68, 'ham': 109}, 'in': {'spam': 66, 'ham': 673}, 'bugis': {'spam': 1, 'ham': 7}, 'n': {'spam': 25, 'ham': 126}, 'great': {'spam': 7, 'ham': 88}, 'world': {'spam': 2, 'ham': 33}, 'la': {'spam': 4, 'ham': 6}, 'e': {'spam': 14, 'ham': 71}, 'buffet': {'spam': 1, 'ham': 3}, 'cine': {'spam': 1, 'ham': 8}, 'there': {'spam': 13, 'ham': 156}, 'got': {'spam': 5, 'ham': 199}, 'amore': {'spam': 1, 'ham': 2}, 'wat': {'spam': 1, 'ham': 77}, 'ok': {'spam': 6, 'ham': 225}, 'lar': {'spam': 1, 'ham': 34}, 'joking': {'spam': 1, 'ham': 4}, 'wif': {'spam': 1, 'ham': 23}, 'u': {'spam': 149, 'ham': 820}, 'oni': {'spam': 1, 'ham': 4}, 'free': {'spam': 186, 'ham': 48}, 'entry': {'spam': 22, 'ham': 1}, 'a': {'spam': 316, 'ham': 886}, 'wkly': {'spam': 10, 'ham': 1}, 'comp': {'spam': 8, 'ham': 3}, 'to': {'spam': 567, 'ham': 1286}, 'win': {'spam': 62, 'ham': 10}, 'fa': {'spam': 5, 'ham': 1}, 'cup': {'spam': 6, 'ham': 5}, 'final': {'spam': 15, 'ham': 3}, 'tkts': {'spam': 5, 'ham': 1}, 'st': {'spam': 27, 'ham': 18},
}
Now that we have a dictionary of probabilities we can now try everything again.
Testing Accuracy
Before I talk about my other algorithms here is a look at how I tested their accuracy. I created a function called test_accuracy that would take in another function (the algorithm) as its argument and some data (training data). Every algorithm version I tested I imported into the jupyter notebook and passed in through the test_accuracy along with the training data. What test accuracy did
def get_accuracy(algorithm, data):
# ammount correct for each label
correct_ham = 0
correct_spam = 0
correct = 0
# the occurances of each label in the data set
spam = len(data.groupby(['true_category']).get_group('spam'))
ham = len(data.groupby(['true_category']).get_group('ham'))
# lenght of the dataset
len_of_data = len(data)
for i in range(len(data)):
# get the message and label
sms = data['message'][i]
label = data['true_category'][i]
# call function
prediction = algorithm(sms) # this returns "spam" or "ham"
if prediction == label:
# If prediction is correct we add 1 overall correct
correct += 1
if prediction == 'spam':
# If the predicted label is spam and acutal label
# is spam then we add to amount correct for spam
correct_spam +=1
elif prediction =='ham':
# If the predicted label is ham and acutal label
# is spam then we add to amount correct for ham
correct_ham +=1
print((correct_ham+correct_spam)/2)
print('Correct Ham: ', + correct_ham/ham)
print('Correct Spam: ', + correct_spam/spam)
print('Correct: ', + correct/len_of_data)
All other attempts with different algorithms
Every algorithm follewd the same proccess as the first one. We sould set the data into dictionary form, count up words and their probabilities and see what we could do with that after.
**Naive Bayes ** One of my attempts was using naive bayes. Naye bayes is a The equation is given by
\[p(c|x) = \frac{p(x|c)p(c)}{p(x)}\]**Removing Stop Words **
I went online and did some more research to see what other things people did. One of the things that I noticed was people removed stop words. I don’t necessarily know by definition what stop words are but from my understanding they are very common words such as the, is, they, etc. So for my next idea to try and improve my algorithms accuracy I removed the stop words. The process of removing the stop words was done along with cleaning the message. In the end this really had no effect and gave me the same results my previous algorithm.
Here are the results

**Graphing the data ** Graphed the word probabilites to see if it could show something (final algorithm)
Lastly I tried graphing the data to see if it would show me anything that I could use to help me. What I did was I got the values of a message both their spam and ham value. I graphed each message with x being their ham value and y being their spam value.
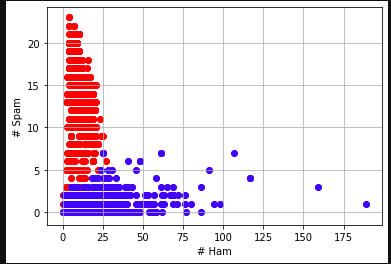
As you can see most messages that are spam have a spam value of 5 and up so I made it that every message with 5 or more spam value is spam and here are the results.

Instead of using some constant like I previously did such as 5 or 10 or 15 to label a message as spam, I could get the average amount of spam words in a spam message in the data and use that. For example I could have a function that takes in all the spam messages and check how many spam words are in a spam message. I could then take the average and set that as my number. Using a constant could hurt the results by possibly underfitting.
Using Scikitlearn Naive Bayees Once I finally got really good results on an algorithm I decided to use a scikit learn. Scikit learn is a machine learning library that makes modeling a lot easier. This was my first time using this library seeing how it’s my first machine learning project so I went online to see how I can use it.
Challenges/What I learned
One of the challenges I faced was not knowing anything about machine learning. This was my first machine learning project and I had only heard about it but never understood how it works, how people go about starting solving their problem, I didn’t know what supervised and unsupervised ML was, I was just very lost. As I read and did more research I learned a lot tho. This first machine learning project has taught me a lot and has been very beneficial to learn about basic machine learning concepts and practices.
Future improvements
Not an improvement but while doing research I found out that this same algorithm could possibly work with classifying whether a sentence is positive or negative like if what someone is saying is good or bad. One thing I’d also like to do is make a visual or see what are the most common words in spam messages and what are the most common in ham. I also mentioned the improvement earlier about finding the average value of a spam message and using that as a cut of level instead of looking at the data and manually putting a number in